Showing results for "ui"














Lessons
view all ⭢



lesson
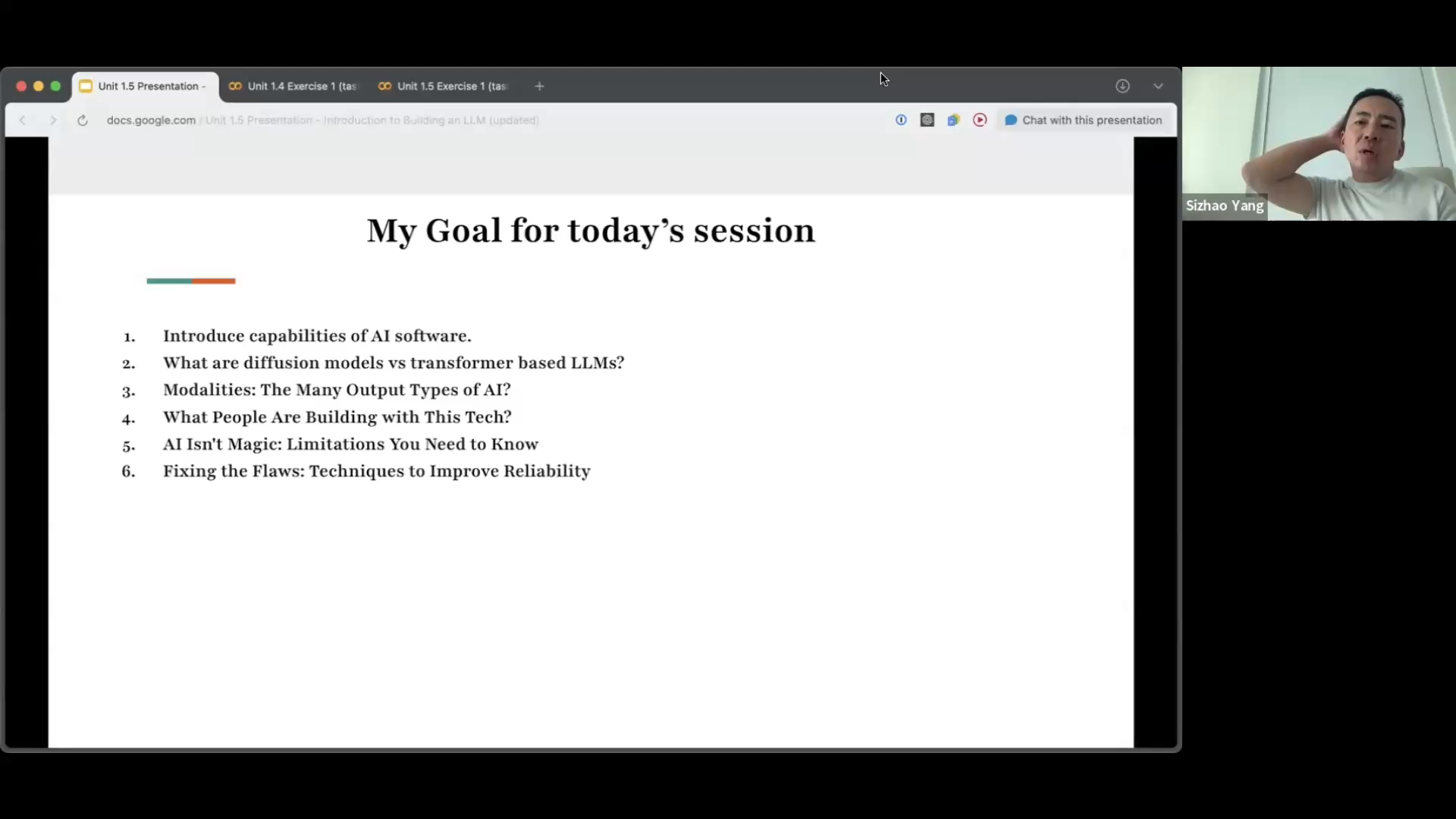
Introduction to Building an LLMPower AI course- Intuition for decoder-only LLMs - Tokens, embeddings, transformer pipeline - Autoregressive next-token generation - Generative AI modalities overview - Diffusion vs transformer model families - Inference flow and prompt processing - Build a real LLM inference API - Architecture: attention, context, decoding - Training phases: pretrain to RLHF - Vertical vs generic LLM design - Distillation, quantization, efficient scaling - Reasoning models: Chain of Thought and Test Time Compute - Hands on Exercises

lesson
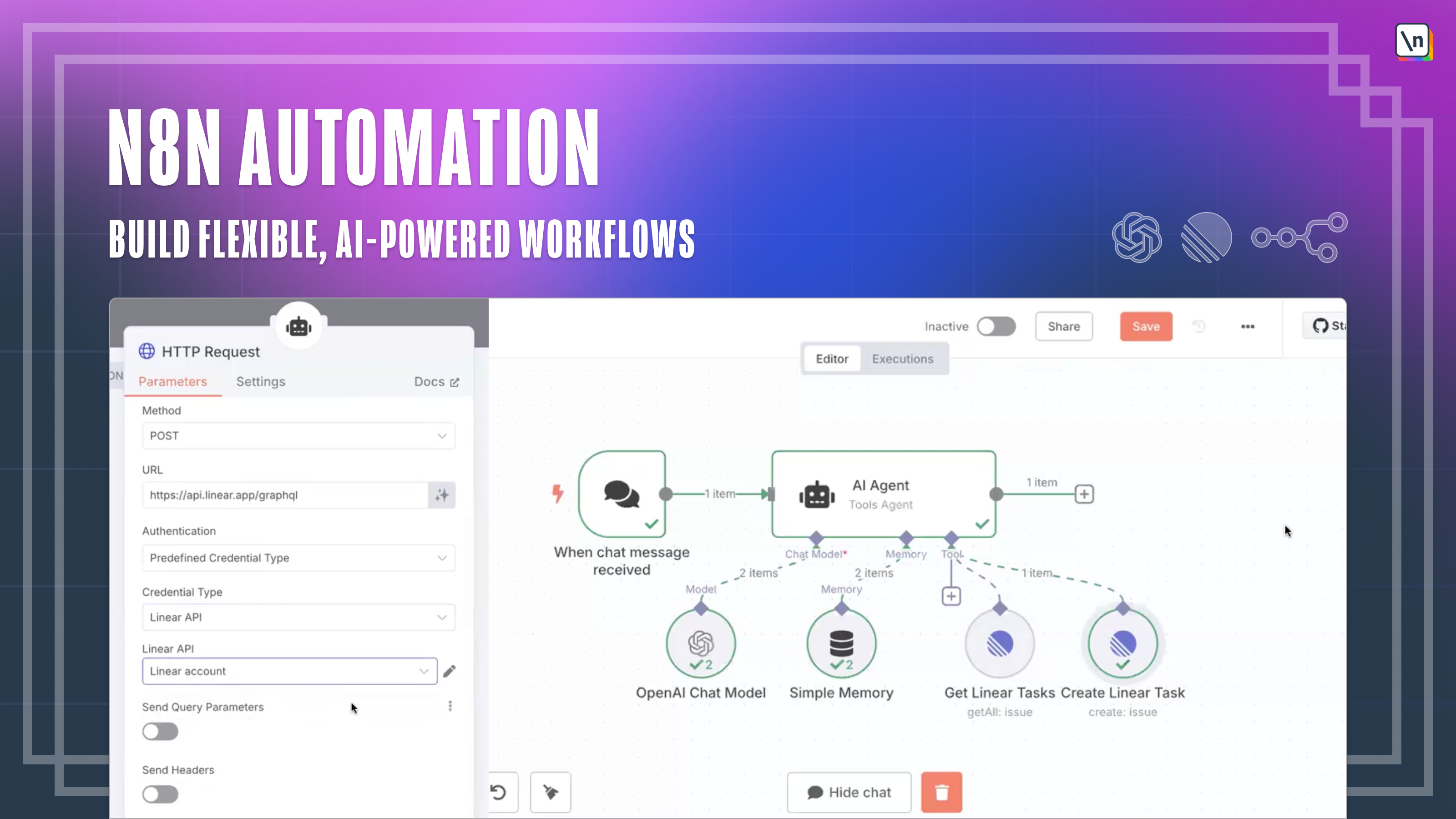
Building AI Code Agents — Case Studies from Copilot, Cursor, WindsurfAI Accelerator- Reverse engineer modern code agents like Copilot, Cursor, Windsurf, and Augment Code - Compare transformer context windows vs RAG + AST-powered systems - Learn how indexing, retrieval, caching, and incremental compilation create agentic coding experiences - Explore architecture of knowledge graphs, graph-based embeddings, and execution-aware completions - Design your own multi-agent AI IDE stack: chunking, AST parsing, RAG + LLM collaboration
lesson
Building Self-Attention LayersAI Accelerator- Understand the motivation for attention: limitations of fixed-window n-gram models - Explore how word meaning changes with context using static vs contextual embeddings (e.g., "bank" problem) - Learn the mechanics of self-attention: Query, Key, Value, dot products, and weighted sums - Manually compute attention scores and visualize how softmax creates probabilistic context focus - Implement self-attention layers in PyTorch using toy examples and evaluate outputs - Visualize attention heatmaps using real LLMs to interpret which words the model attends to - Compare loss curves of self-attention models vs trigram models and observe learning dynamics - Understand how embeddings evolve through transformer layers and extract them using GPT-2 - Build both single-head and multi-head transformer models; compare their predictions and training performance - Implement a Mixture-of-Experts (MoE) attention model and observe gating behavior on different inputs - Evaluate self-attention vs MoE vs n-gram models on fluency, generalization, and loss curves - Run meta-evaluation across all models to compare generation quality and training stability
lesson
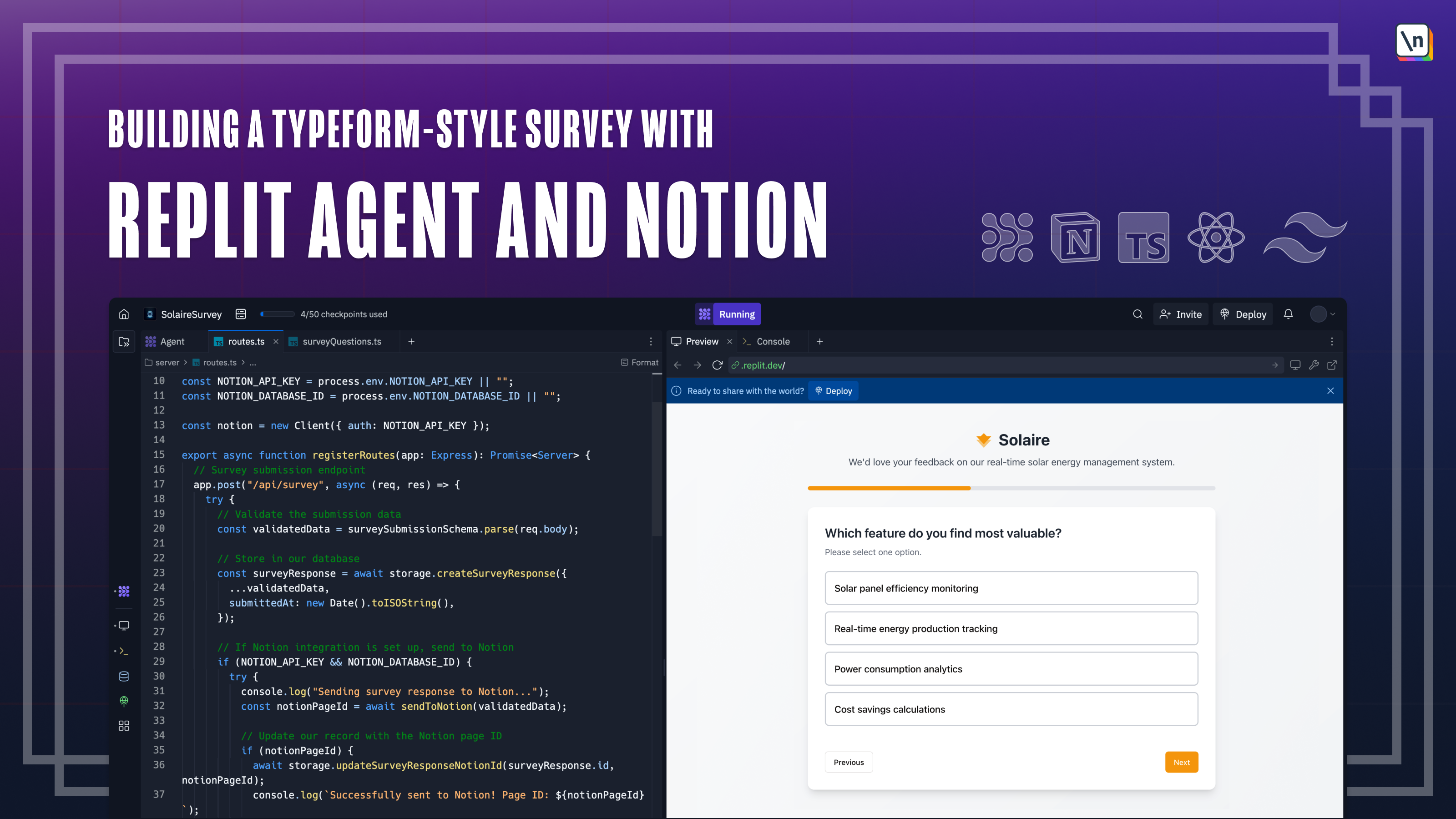
From Theory to Practice — Building Your First LLM ApplicationAI Accelerator- Understand how inference works in LLMs (prompt processing vs. autoregressive decoding) - Explore real-world AI applications: RAG, vertical models, agents, multimodal tools - Learn the five phases of the model lifecycle: pretraining to RLHF to evaluation - Compare architecture types: generic LLMs vs. ChatGPT vs. domain-specialized models - Work with tools like Hugging Face, Modal, and vector databases - Build a “Hello World” LLM inference API using OPT-125m on Modal